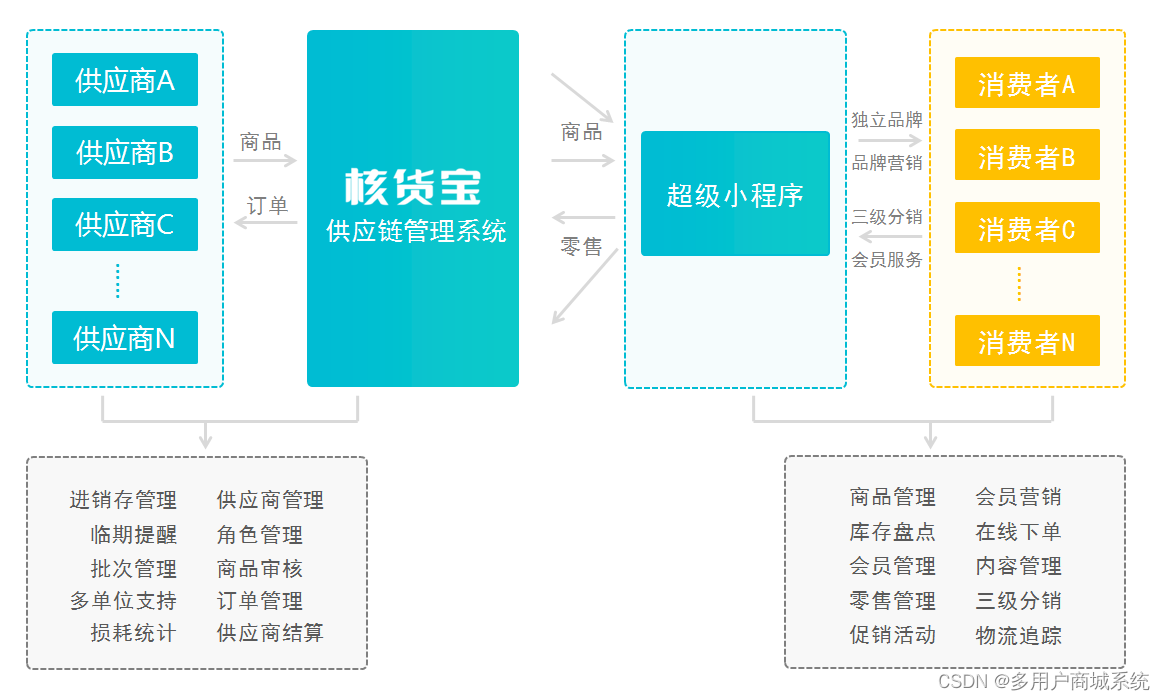
数据集链接:https://pan.baidu.com/s/19Uxc2ELiMG3acUtLeSTDTA?pwd=wsyw
提取码:wsyw
我设置的图片大小为128*128,如果内存爆炸可以将batch_size调小,epoch我设置的2000,我感觉其实1000也够了。代码如下:
import argparse
from torchvision import datasets, transforms
import torch
import torch.nn as nn
import os
import numpy as np
from torchvision.utils import save_image
def args_parse():
parser = argparse.ArgumentParser()
parser.add_argument("--n_epoches", type=int, default=2000, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=256, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--n_cpu", type=int, default=1, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--img_size", type=int, default=128, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=3, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=50, help="interval between image sampling")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--type", type=str, default='DCGAN', help="The type of DCGAN")
return parser.parse_args()
class Generator(nn.Module):
def __init__(self, latent_dim, img_shape):
super(Generator, self).__init__()
self.img_shape = img_shape
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(latent_dim, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.size(0), self.img_shape[0], self.img_shape[1], self.img_shape[2])
return img
class Discriminator(nn.Module):
def __init__(self, img_shape):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid(),
)
def forward(self, img):
img_flat = img.view(img.size(0), -1)
validity = self.model(img_flat)
return validity
class Generator_CNN(nn.Module):
def __init__(self, latent_dim, img_shape):
super(Generator_CNN, self).__init__()
self.init_size = img_shape[1] // 4
self.l1 = nn.Sequential(nn.Linear(latent_dim, 128 * self.init_size ** 2)) # 100 ——> 128 * 8 * 8 = 8192
self.conv_blocks = nn.Sequential(
nn.BatchNorm2d(128),
nn.Upsample(scale_factor=2),
nn.Conv2d(128, 128, 3, stride=1, padding=1),
nn.BatchNorm2d(128, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Upsample(scale_factor=2),
nn.Conv2d(128, 64, 3, stride=1, padding=1),
nn.BatchNorm2d(64, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, img_shape[0], 3, stride=1, padding=1),
nn.Tanh()
)
def forward(self, z):
out = self.l1(z)
out = out.view(out.shape[0], 128, self.init_size, self.init_size)
img = self.conv_blocks(out)
return img
class Discriminator_CNN(nn.Module):
def __init__(self, img_shape):
super(Discriminator_CNN, self).__init__()
def discriminator_block(in_filters, out_filters, bn=True):
block = [nn.Conv2d(in_filters, out_filters, 3, 2, 1),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout2d(0.25)]
if bn:
block.append(nn.BatchNorm2d(out_filters, 0.8))
return block
self.model = nn.Sequential(
*discriminator_block(img_shape[0], 16, bn=False),
*discriminator_block(16, 32),
*discriminator_block(32, 64),
*discriminator_block(64, 128),
)
ds_size = img_shape[1] // 2 ** 4
self.adv_layer = nn.Sequential(nn.Linear(128 * ds_size ** 2, 1), nn.Sigmoid()) # 128 * 2 * 2 ——> 1
def forward(self, img):
out = self.model(img)
out = out.view(out.shape[0], -1)
# print('out:', out.shape)
validity = self.adv_layer(out)
return validity
def train():
opt = args_parse()
transform = transforms.Compose(
[
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5])
])
data = datasets.ImageFolder('./dataset', transform=transform)
train_loader = torch.utils.data.DataLoader(
data,
batch_size=opt.batch_size,
shuffle=True)
img_shape = (opt.channels, opt.img_size, opt.img_size)
# Construct generator and discriminator
if opt.type == 'DCGAN':
generator = Generator_CNN(opt.latent_dim, img_shape)
discriminator = Discriminator_CNN(img_shape)
else:
generator = Generator(opt.latent_dim, img_shape)
discriminator = Discriminator(img_shape)
adversarial_loss = torch.nn.BCELoss()
cuda = True if torch.cuda.is_available() else False
if cuda:
generator.cuda()
discriminator.cuda()
adversarial_loss.cuda()
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=(opt.lr * 8 / 9), betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
for epoch in range(opt.n_epoches):
for i, (imgs, _) in enumerate(train_loader):
# adversarial ground truths
valid = torch.ones(imgs.shape[0], 1).type(Tensor)
fake = torch.zeros(imgs.shape[0], 1).type(Tensor)
real_imgs = imgs.type(Tensor)
############# Train Generator ################
optimizer_G.zero_grad()
# sample noise as generator input
z = torch.tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim))).type(Tensor)
# Generate a batch of images
gen_imgs = generator(z)
# G-Loss
g_loss = adversarial_loss(discriminator(gen_imgs), valid)
g_loss.backward()
optimizer_G.step()
############# Train Discriminator ################
optimizer_D.zero_grad()
# D-Loss
real_loss = adversarial_loss(discriminator(real_imgs), valid)
fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake)
d_loss = (real_loss + fake_loss) / 2
d_loss.backward()
optimizer_D.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G Loss: %f]"
% (epoch, opt.n_epoches, i, len(train_loader), d_loss.item(), g_loss.item())
)
batches_done = epoch * len(train_loader) + i
os.makedirs("images_3_2", exist_ok=True)
if batches_done % opt.sample_interval == 0:
save_image(gen_imgs.data[:25], "images_3_2/%d.png" % (batches_done), nrow=5, normalize=True)
if __name__ == '__main__':
train()
实验效果如下: